引言:本文主要介绍ICLR2021论文《AN IMAGE IS WORTH 16X16 WORDS: TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE》。
概述
这篇文章,也就是大名鼎鼎的ViT,是把在NLP领域中炙手可热的transformer引入CV领域的开篇之作,也是经典的挖坑之作,值得精读。
综述
作者开篇介绍了CNN在视觉领域的统治地位,启发于transformer在NLP领域的卓越表现,有人将自注意力机制嵌入CNN中,也有人用自注意力完全取代卷积,但是这些都经过了个性化的修改,目前还没有对应的加速算子。作者自己完全把transformer搬过来,不作任何修改,而是修改输入,他们把图像分成一个一个的patch平铺开,然后经过一个linear embedding,这样来模仿一个token,作为transformer的输入,并用监督方式训练了图像分类任务。
作者在小数据集上训练效果较差,他们认为主要是transformer没有了CNN的归纳偏置:局部相关性和平移等变性。这里的归纳偏置(inductive biases)其实就是人类的先验,在CNN的设计中很多地方体现了这种先验,比如卷积核,就是认为图像具有局部性,离得越近的像素相关性越强。transformer没有利用这种性质,所以在小数据集上学习不够充分,所以效果不好。
最后在大数据集ImageNet-21k和JFT-300M上预训练之后,然后在许多数据集上finetune都取得了超越CNN的效果。
相关工作
先介绍了transformer在NLP领域的成果,GPT,BERT等。但是在CV领域自注意力复杂度与图像尺寸的平方成正比,计算量非常大,之前有人采用了只在局部进行自注意力的方法,也有采用稀疏自注意力的方法,也有在一个block内部采用自注意力的方法,虽然效果不错,但是这些方法的工程实现非常复杂,而且硬件加速很不友好。然后介绍了一篇与自己的工作非常相似的文章,但是那篇文章只是在尺寸较小的图像上进行了实验,不适用大尺寸图像,而且作者对预训练进行了更加深入的论证。
方法
作者说他们的方法基本上没有对原始的transformer进行改动,可以拿过来开箱即用。
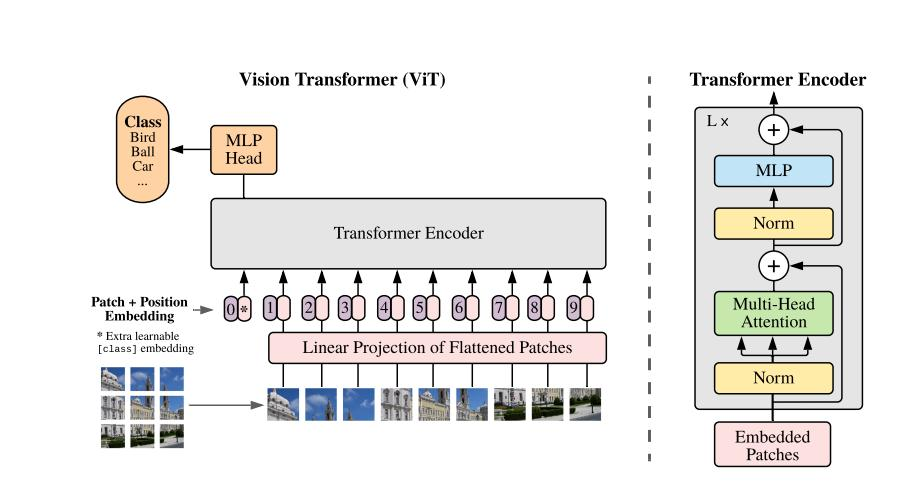
这张图画的非常好,可以从这张图清晰的看出作者的整个设计思路。先将图像分成一个个patch,这样每个patch的通道数量就是PxPx3,这里的P是每个patch的边长,然后把这个patch经过一个linear embedding层也就是一个全连接层,这样通道数量就变成了D。经过上述操作之后,每个输入就变成了一个1D的token,和NLP中的输入类似。
参照BERT的做法,额外增加了一个可学习的类别token,用来作最终的分类,因为transformer的自注意力是全局的,所以这个类别token具有全局信息,这样是合理的,消融实验证明采用全局平均池化的方式代替这个额外的类别token效果也是差不多的,但是还是那一点,为了保持一致。
因为transformer不想卷积一样具有位置信息,所以在输入上额外增加了一个位置编码,这里作者采用的是一个1D的位置编码,消融实验证明用2D位置编码效果并没有什么提升。
transformer编码器采用的是多头自注意力+MLP,而且每个块之前都用了LayerNorm,同时采用了残差连接的方式,MLP采用的是GELU激活函数。
在这里,作者又详细说明了他们所设计的网络结构并没有太多图像相关的归纳偏置,只有MLP是局部和平移等变的,像自注意力是全局的,而且每个patch被平铺开,并没有携带2D信息,所以这些patch的空间相关性需要从头学习。
基于上述问题,作者给出了一种变体实现方法,就是不把原始图像打成patch,而是用一个普通的CNN,最后得到的特征图和处理成patch是一样大小的,然后在经过一个linear embedding丢给transformer,后面其他操作是一样的,这样就携带了空间信息。
最后作者提到预训练时在更大的图像上效果会更好,保持patch尺寸不变,这样patch数量就会增加,之前的位置编码可能会没用,这里作者采用的是直接插值的方式,但是这其实是一种临时的解决策略,因为当尺寸变得很大时,这种直接插值的方式会掉点。这里的分辨率调整和抽图像块是ViT唯一使用到的2D信息的归纳偏置。
实验
作者在三个数据上进行了预训练:分别是ImageNet-1K,ImageNet-221K和JFT,数量分别是130万,1400万和3亿,并且在许多流行的数据集上进行了评测。他们的模型一共有三种变体:Base,Large和Huge,主要是层数,D,MLP尺寸,多头自注意力的头数不同。然后从表现和训练成本进行了对比说明,表现效果略好,但是训练相较于其他的要快不少。
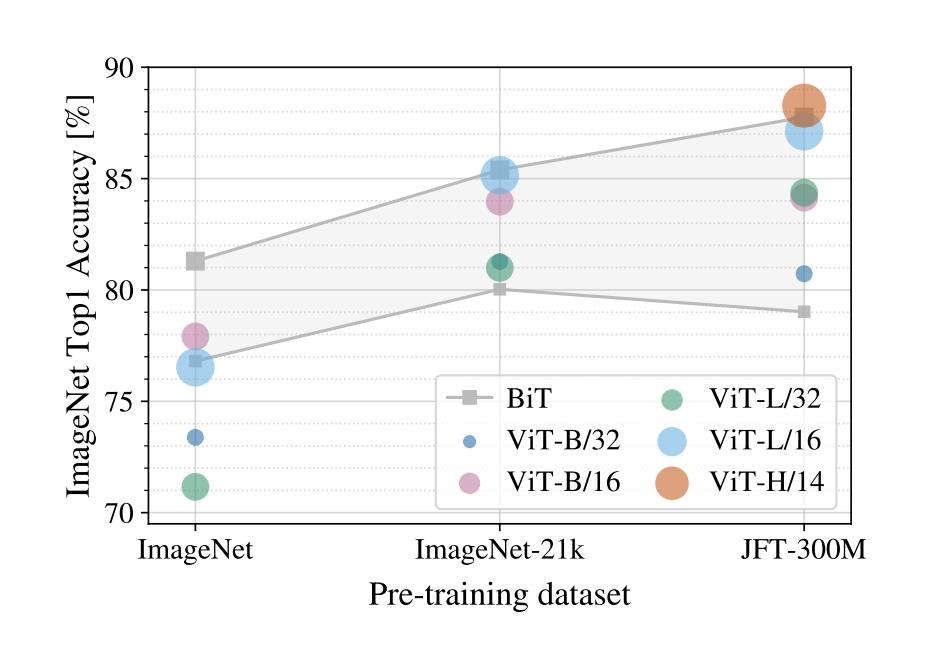
这张图可以说是这篇文章的精髓了,当在较小的数据集上训练时,transformer的效果明显不如CNN,当在数据量适中的数据集上训练时,效果基本上就和CNN持平了,当在更大的数据集上训练时,效果就会优于CNN,而且没有收敛的迹象。
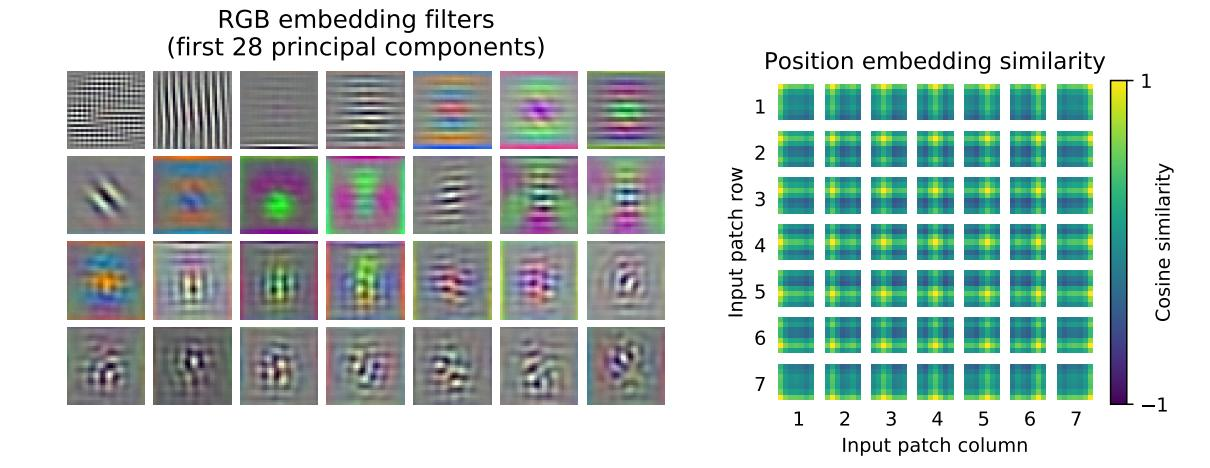
之后进行了可视化分析,linear embedding类似与CNN,提取到的都是类似于Gabor滤波器提取到的特征,比如颜色纹理等,位置编码用1D位置编码,却已经学到了2D的特征,这也就解释了为什么用1D就够了。
最后,作者着重说明了自监督训练,这也是transformer能这么火的原因,作者采用masked patch方法进行自监督,效果并没有达到预期。
结论
作者对自己的工作作了总结,并指明了几个可以进一步研究的方向,比如下游任务如检测分割等,比如自监督预训练,又比如架构和目标函数等等。