for t in chain(self.module.parameters(), self.module.buffers()): if t.device != self.src_device_obj: raise RuntimeError("module must have its parameters and buffers " "on device {} (device_ids[0]) but found one of " "them on device: {}".format(self.src_device_obj, t.device))
defscatter(inputs, target_gpus, dim=0): r""" Slices tensors into approximately equal chunks and distributes them across given GPUs. Duplicates references to objects that are not tensors. """ defscatter_map(obj): ifisinstance(obj, torch.Tensor): return Scatter.apply(target_gpus, None, dim, obj) if is_namedtuple(obj): return [type(obj)(*args) for args inzip(*map(scatter_map, obj))] ifisinstance(obj, tuple) andlen(obj) > 0: returnlist(zip(*map(scatter_map, obj))) ifisinstance(obj, list) andlen(obj) > 0: return [list(i) for i inzip(*map(scatter_map, obj))] ifisinstance(obj, dict) andlen(obj) > 0: return [type(obj)(i) for i inzip(*map(scatter_map, obj.items()))] return [obj for targets in target_gpus]
# After scatter_map is called, a scatter_map cell will exist. This cell # has a reference to the actual function scatter_map, which has references # to a closure that has a reference to the scatter_map cell (because the # fn is recursive). To avoid this reference cycle, we set the function to # None, clearing the cell try: res = scatter_map(inputs) finally: scatter_map = None return res
@staticmethod defforward(ctx, target_gpus, chunk_sizes, dim, input): target_gpus = [_get_device_index(x, True) for x in target_gpus] ctx.dim = dim ctx.input_device = input.get_device() ifinput.device.type != "cpu"else -1 streams = None if torch.cuda.is_available() and ctx.input_device == -1: # Perform CPU to GPU copies in a background stream
# 新建 cuda stream streams = [_get_stream(device) for device in target_gpus]
# Synchronize with the copy stream if streams isnotNone: for i, output inenumerate(outputs): with torch.cuda.device(target_gpus[i]): main_stream = torch.cuda.current_stream() main_stream.wait_stream(streams[i]) output.record_stream(main_stream) return outputs
# 现在开始拷贝网络 # 准备过程:将 network.modules() 变成list # 然后再为之后复制的模型准备好空的 list 和 indices
modules = list(network.modules()) module_copies = [[] for device in devices] module_indices = {} scriptmodule_skip_attr = {"_parameters", "_buffers", "_modules", "forward", "_c"}
for i, module inenumerate(modules): module_indices[module] = i for j inrange(num_replicas): replica = module._replicate_for_data_parallel() # This is a temporary fix for DDP. DDP needs to access the # replicated model parameters. It used to do so through # `mode.parameters()`. The fix added in #33907 for DP stops the # `parameters()` API from exposing the replicated parameters. # Hence, we add a `_former_parameters` dict here to support DDP. replica._former_parameters = OrderedDict()
module_copies[j].append(replica)
# 接下来分别复制 module,param,buffer for i, module inenumerate(modules): for key, child in module._modules.items(): if child isNone: for j inrange(num_replicas): replica = module_copies[j][i] replica._modules[key] = None else: module_idx = module_indices[child] for j inrange(num_replicas): replica = module_copies[j][i] setattr(replica, key, module_copies[j][module_idx]) for key, param in module._parameters.items(): if param isNone: for j inrange(num_replicas): replica = module_copies[j][i] replica._parameters[key] = None else: param_idx = param_indices[param] for j inrange(num_replicas): replica = module_copies[j][i] param = param_copies[j][param_idx] # parameters in replicas are no longer leaves, # so setattr them as non-parameter attributes setattr(replica, key, param) # expose the parameter for DDP replica._former_parameters[key] = param for key, buf in module._buffers.items(): if buf isNone: for j inrange(num_replicas): replica = module_copies[j][i] replica._buffers[key] = None else: if buf.requires_grad andnot detach: buffer_copies = buffer_copies_rg buffer_idx = buffer_indices_rg[buf] else: buffer_copies = buffer_copies_not_rg buffer_idx = buffer_indices_not_rg[buf] for j inrange(num_replicas): replica = module_copies[j][i] setattr(replica, key, buffer_copies[j][buffer_idx])
return [module_copies[j][0] for j inrange(num_replicas)]
# 先看 else 的 comment,因为不 detach 也会用到同样的函数 if detach: return comm.broadcast_coalesced(tensors, devices) else: # Use the autograd function to broadcast if not detach iflen(tensors) > 0:
return [tensor_copies[i:i + len(tensors)] for i inrange(0, len(tensor_copies), len(tensors))] else: return []
# Broadcast.apply classBroadcast(Function):
@staticmethod defforward(ctx, target_gpus, *inputs): assertall(i.device.type != 'cpu'for i in inputs), ( 'Broadcast function not implemented for CPU tensors' ) target_gpus = [_get_device_index(x, True) for x in target_gpus] ctx.target_gpus = target_gpus iflen(inputs) == 0: returntuple() ctx.num_inputs = len(inputs) # input 放在 device[0] ctx.input_device = inputs[0].get_device()
non_differentiables = [] for idx, input_requires_grad inenumerate(ctx.needs_input_grad[1:]): ifnot input_requires_grad: for output in outputs: non_differentiables.append(output[idx]) ctx.mark_non_differentiable(*non_differentiables) returntuple([t for tensors in outputs for t in tensors])
# 源码 defgather(outputs, target_device, dim=0): r""" Gathers tensors from different GPUs on a specified device (-1 means the CPU). """ defgather_map(outputs): out = outputs[0] ifisinstance(out, torch.Tensor): return Gather.apply(target_device, dim, *outputs) if out isNone: returnNone ifisinstance(out, dict): ifnotall((len(out) == len(d) for d in outputs)): raise ValueError('All dicts must have the same number of keys') returntype(out)(((k, gather_map([d[k] for d in outputs])) for k in out)) returntype(out)(map(gather_map, zip(*outputs)))
# Recursive function calls like this create reference cycles. # Setting the function to None clears the refcycle. try: res = gather_map(outputs) finally: gather_map = None return res
# Gather 源码
classGather(Function):
@staticmethod defforward(ctx, target_device, dim, *inputs): assertall(i.device.type != 'cpu'for i in inputs), ( 'Gather function not implemented for CPU tensors' )
ctx.dim = dim ctx.input_gpus = tuple(i.get_device() for i in inputs)
ifall(t.dim() == 0for t in inputs) and dim == 0: inputs = tuple(t.view(1) for t in inputs) warnings.warn('Was asked to gather along dimension 0, but all ' 'input tensors were scalars; will instead unsqueeze ' 'and return a vector.') ctx.unsqueezed_scalar = True else: ctx.unsqueezed_scalar = False ctx.input_sizes = tuple(i.size(ctx.dim) for i in inputs) return comm.gather(inputs, ctx.dim, ctx.target_device)
@staticmethod defbackward(ctx, grad_output): scattered_grads = Scatter.apply(ctx.input_gpus, ctx.input_sizes, ctx.dim, grad_output) if ctx.unsqueezed_scalar: scattered_grads = tuple(g[0] for g in scattered_grads) return (None, None) + scattered_grads
# comm.gather 涉及到 C++,具体实现咱也不讲了 ;) # Gathers tensors from multiple GPU devices. defgather(tensors, dim=0, destination=None, *, out=None): tensors = [_handle_complex(t) for t in tensors] if out isNone: if destination == -1: warnings.warn( 'Using -1 to represent CPU tensor is deprecated. Please use a ' 'device object or string instead, e.g., "cpu".') destination = _get_device_index(destination, allow_cpu=True, optional=True) return torch._C._gather(tensors, dim, destination) else: if destination isnotNone: raise RuntimeError( "'destination' must not be specified when 'out' is specified, but " "got destination={}".format(destination)) return torch._C._gather_out(tensors, out, dim)
The difference between DistributedDataParallel and DataParallel is: DistributedDataParallel uses multiprocessing where a process is created for each GPU, while DataParallel uses multithreading. By using multiprocessing, each GPU has its dedicated process, this avoids the performance overhead caused by GIL of Python interpreter.
全局解释器锁,简单来说就是,一个 Python 进程只能利用一个 CPU kernel,即单核多线程并发时,只能执行一个线程。考虑多核,多核多线程可能出现线程颠簸 (thrashing) 造成资源浪费,所以 Python 想要利用多核最好是多进程。
assertany((p.requires_grad for p in module.parameters())), ( "DistributedDataParallel is not needed when a module " "doesn't have any parameter that requires a gradient." )
self.is_multi_device_module = len({p.device for p in module.parameters()}) > 1 distinct_device_types = {p.device.typefor p in module.parameters()} assertlen(distinct_device_types) == 1, ( "DistributedDataParallel's input module must be on " "the same type of devices, but input module parameters locate in {}." ).format(distinct_device_types) self.device_type = list(distinct_device_types)[0]
if self.device_type == "cpu"or self.is_multi_device_module: assertnot device_ids andnot output_device, ( "DistributedDataParallel device_ids and output_device arguments " "only work with single-device GPU modules, but got " "device_ids {}, output_device {}, and module parameters {}." ).format(device_ids, output_device, {p.device for p in module.parameters()})
self.device_ids = None self.output_device = None else: # Use all devices by default for single-device GPU modules if device_ids isNone: device_ids = _get_all_device_indices()
if check_reduction: # This argument is no longer used since the reducer # will ensure reduction completes even if some parameters # do not receive gradients. warnings.warn( "The `check_reduction` argument in `DistributedDataParallel` " "module is deprecated. Please avoid using it." ) pass
# used for intra-node param sync and inter-node sync as well self.broadcast_bucket_size = int(250 * 1024 * 1024)
def_ddp_init_helper(self): """ Initialization helper function that does the following: (1) replicating the module from device[0] to the other devices (前文提到 DDP 也支持一个进程多线程利用多卡,类似 DP ,这时候就会用到第一步) (2) bucketing the parameters for reductions (把 parameter 分组,梯度通讯时,先得到梯度的会通讯) (3) resetting the bucketing states (4) registering the grad hooks (创建管理器) (5) passing a handle of DDP to SyncBatchNorm Layer (为 SyncBN 准备) """
defparameters(m, recurse=True): defmodel_parameters(m): ps = m._former_parameters.values() \ ifhasattr(m, "_former_parameters") \ else m.parameters(recurse=False) for p in ps: yield p
for m in m.modules() if recurse else [m]: for p in model_parameters(m): yield p
if self.device_ids andlen(self.device_ids) > 1:
warnings.warn( "Single-Process Multi-GPU is not the recommended mode for " "DDP. In this mode, each DDP instance operates on multiple " "devices and creates multiple module replicas within one " "process. The overhead of scatter/gather and GIL contention " "in every forward pass can slow down training. " "Please consider using one DDP instance per device or per " "module replica by explicitly setting device_ids or " "CUDA_VISIBLE_DEVICES. " )
# only create replicas for single-device CUDA modules # # TODO: we don't need to replicate params in here. they're always going to # be broadcasted using larger blocks in broadcast_coalesced, so it might be # better to not pollute the caches with these small blocks self._module_copies = replicate(self.module, self.device_ids, detach=True) self._module_copies[0] = self.module
for module_copy in self._module_copies[1:]: for param, copy_param inzip(self.module.parameters(), parameters(module_copy)): # Reducer requires param copies have the same strides across replicas. # Fixes up copy_param strides in case replicate didn't match param strides. if param.layout is torch.strided and param.stride() != copy_param.stride(): with torch.no_grad(): copy_param.set_(copy_param.clone() .as_strided(param.size(), param.stride()) .copy_(copy_param)) copy_param.requires_grad = param.requires_grad
else: self._module_copies = [self.module]
self.modules_params = [list(parameters(m)) for m in self._module_copies] self.modules_buffers = [list(m.buffers()) for m in self._module_copies]
# Build tuple of (module, parameter) for all parameters that require grads. modules_and_parameters = [ [ (module, parameter) for module in replica.modules() for parameter infilter( lambda parameter: parameter.requires_grad, parameters(module, recurse=False)) ] for replica in self._module_copies]
# Build list of parameters. parameters = [ list(parameter for _, parameter in replica) for replica in modules_and_parameters]
# Checks if a module will produce a sparse gradient. defproduces_sparse_gradient(module): ifisinstance(module, torch.nn.Embedding): return module.sparse ifisinstance(module, torch.nn.EmbeddingBag): return module.sparse returnFalse
# Build list of booleans indicating whether or not to expect sparse # gradients for the corresponding parameters. expect_sparse_gradient = [ list(produces_sparse_gradient(module) for module, _ in replica) for replica in modules_and_parameters]
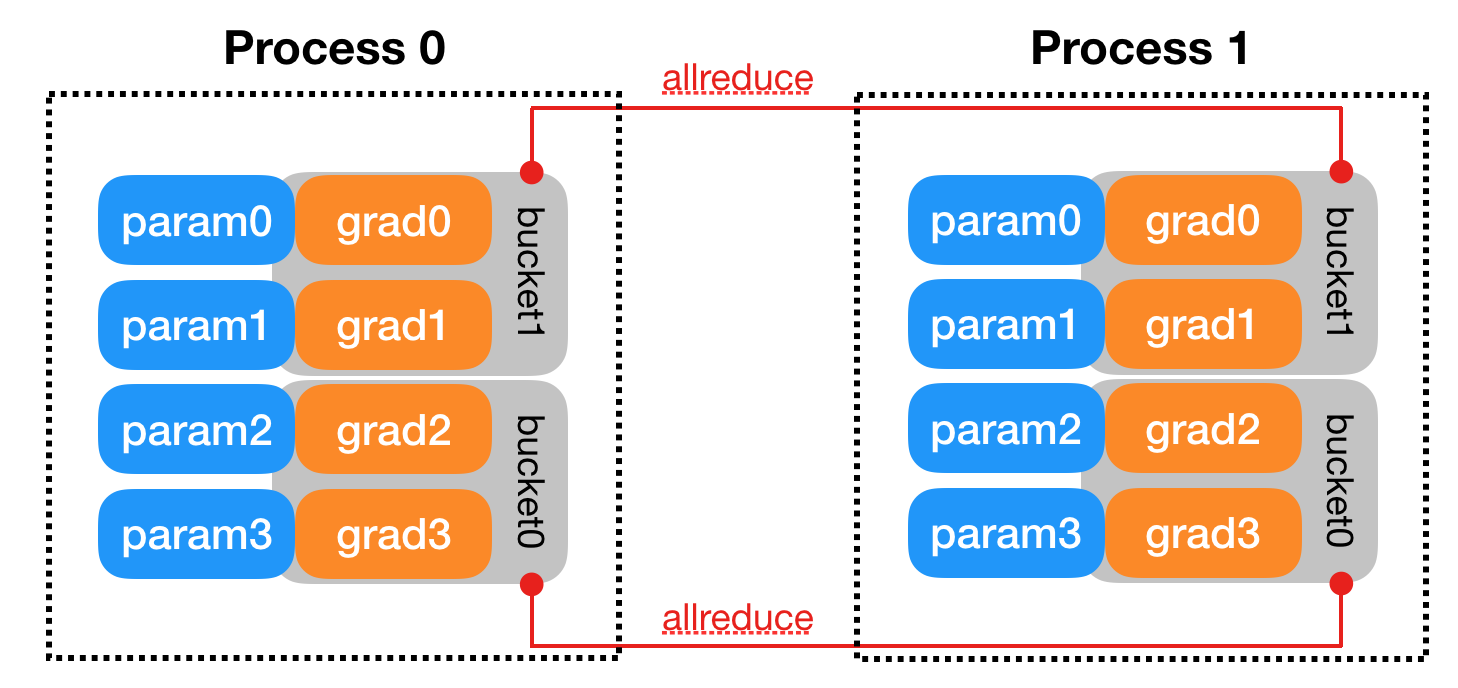
# The bucket size limit is specified in the constructor. # Additionally, we allow for a single small bucket for parameters # that are defined first, such that their gradients don't spill into # a much larger bucket, adding unnecessary latency after gradient # computation finishes. Experiments showed 1MB is a reasonable value. bucket_indices = dist._compute_bucket_assignment_by_size( parameters[0], [dist._DEFAULT_FIRST_BUCKET_BYTES, self.bucket_bytes_cap], expect_sparse_gradient[0])
# Note: reverse list of buckets because we want to approximate the # order in which their gradients are produced, and assume they # are used in the forward pass in the order they are defined. # 管理器 self.reducer = dist.Reducer( parameters, list(reversed(bucket_indices)), self.process_group, expect_sparse_gradient, self.bucket_bytes_cap, self.find_unused_parameters, self.gradient_as_bucket_view)
# passing a handle to torch.nn.SyncBatchNorm layer self._passing_sync_batchnorm_handle(self._module_copies)
// The gradient accumulator function is lazily initialized once. // Therefore we can use its presence in the autograd graph as // evidence that the parameter has participated in an iteration. auto grad_accumulator = torch::autograd::impl::grad_accumulator(variable);
// Map raw function pointer to replica index and parameter index. // This is used later on when the autograd graph is traversed // to check for parameters for which no gradient is computed. func_[grad_accumulator.get()] = index;
// The gradient accumulator is stored as weak_ptr in the autograd // metadata of the variable, so we have to keep it alive here for // the raw pointer to be valid. grad_accumulators_[replica_index][variable_index] = std::move(grad_accumulator); } } }
voidReducer::autograd_hook(VariableIndex index){ std::lock_guard lock(this->mutex_); if (find_unused_parameters_) { // 在 no_sync 时,只要参数被用过一次,就会被标记为用过 // Since it gets here, this param has been used for this iteration. We want // to mark it in local_used_maps_. During no_sync session, the same var can // be set multiple times, which is OK as does not affect correctness. As // long as it is used once during no_sync session, it is marked as used. local_used_maps_[index.replica_index][index.variable_index] = 1; }
// Ignore if we don't expect to be called. // This may be the case if the user wants to accumulate gradients // for number of iterations before reducing them. if (!expect_autograd_hooks_) { return; }
// Rebuild bucket only if 1) it is the first time to rebuild bucket 2) // find_unused_parameters_ is false, currently it does not support when there // are unused parameters 3) this backward pass needs to run allreduce. Here, // we just dump tensors and their parameter indices into rebuilt_params_ and // rebuilt_param_indices_ based on gradient arriving order, and then at the // end of finalize_backward(), buckets will be rebuilt based on // rebuilt_params_ and rebuilt_param_indices_, and then will be broadcasted // and initialized. Also we only need to dump tensors and parameter indices of // one replica. push_rebuilt_params(index);
// If `find_unused_parameters_` is true there may be model parameters that // went unused when computing the model output, they won't be part of the // autograd graph, and won't receive gradients. These parameters are // discovered in the `prepare_for_backward` function and their indexes stored // in the `unused_parameters_` vector. if (!has_marked_unused_parameters_ && find_unused_parameters_) { has_marked_unused_parameters_ = true; for (constauto& unused_index : unused_parameters_) { mark_variable_ready(unused_index); } }
// Finally mark variable for which this function was originally called. mark_variable_ready(index); }
defforward(self, inputs, *kwargs):if self.ddp_join_enabled: ones = torch.ones( 1, device=self.device ) work = dist.all_reduce(ones, group=self.process_group, async_op=True) self.reducer._set_forward_pass_work_handle( work, self.ddp_join_divide_by_initial_world_size ) # Calling _rebuild_buckets before forward compuation, # It may allocate new buckets before deallocating old buckets # inside _rebuild_buckets. To save peak memory usage, # call _rebuild_buckets before the peak memory usage increases # during forward computation. # This should be called only once during whole training period. if self.reducer._rebuild_buckets(): logging.info("Reducer buckets have been rebuilt in this iteration.")
if self.require_forward_param_sync: self._sync_params()
if self.ddp_join_enabled: # Notify joined ranks whether they should sync in backwards pass or not. self._check_global_requires_backward_grad_sync(is_joined_rank=False)
if torch.is_grad_enabled() and self.require_backward_grad_sync: self.require_forward_param_sync = True # We'll return the output object verbatim since it is a freeform # object. We need to find any tensors in this object, though, # because we need to figure out which parameters were used during # this forward pass, to ensure we short circuit reduction for any # unused parameters. Only if `find_unused_parameters` is set. if self.find_unused_parameters: # 当DDP参数 find_unused_parameter 为 true 时,其会在 forward 结束时,启动一个回溯,标记出所有没被用到的 parameter,提前把这些设定为 ready,这样 backward 就可以在一个 subgraph 进行,但这样会牺牲一部分时间。 self.reducer.prepare_for_backward(list(_find_tensors(output))) else: self.reducer.prepare_for_backward([]) else: self.require_forward_param_sync = False
// If it was scheduled, wait on allreduce in forward pass that tells us // division factor based on no. of currently participating processes. if (divFactor_ == kUnsetDivFactor) { divFactor_ = process_group_->getSize(); auto& workHandle = forwardPassWorkHandle_.workHandle; if (workHandle && !forwardPassWorkHandle_.useStaticWorldSize) { workHandle->wait(); auto results = workHandle->result(); // Guard against the results being empty TORCH_INTERNAL_ASSERT(results.size() > 0); at::Tensor& res = results.front(); divFactor_ = res.item().to<int>(); } }
if (bucket.expect_sparse_gradient) { mark_variable_ready_sparse(index); } else { mark_variable_ready_dense(index); }
// 检查桶里的变量是不是都ready了,如果没有东西 pending,那就是都 ready了 if (--replica.pending == 0) { if (--bucket.pending == 0) { mark_bucket_ready(bucket_index.bucket_index); } }
// Run finalizer function and kick off reduction for local_used_maps once the // final bucket was marked ready. if (next_bucket_ == buckets_.size()) { if (find_unused_parameters_) { // H2D from local_used_maps_ to local_used_maps_dev_ for (size_t i = 0; i < local_used_maps_.size(); i++) { // We do async H2D to avoid the blocking overhead. The async copy and // allreduce respect the current stream, so will be sequenced correctly. local_used_maps_dev_[i].copy_(local_used_maps_[i], true); } local_used_work_ = process_group_->allreduce(local_used_maps_dev_); }
// The autograd engine uses the default stream when running callbacks, so we // pass in the current CUDA stream in case it is not the default. c10::DeviceType deviceType = replica.contents.device().type(); const c10::impl::VirtualGuardImpl guard = c10::impl::VirtualGuardImpl{deviceType}; const c10::Stream currentStream = guard.getStream(replica.contents.device()); torch::autograd::Engine::get_default_engine().queue_callback([=] { std::lock_guard<std::mutex> lock(this->mutex_); // Run callback with the current stream c10::OptionalStreamGuard currentStreamGuard{currentStream}; this->finalize_backward(); }); } }
voidReducer::mark_bucket_ready(size_t bucket_index){ TORCH_INTERNAL_ASSERT(bucket_index >= next_bucket_); // Buckets are reduced in sequence. Ignore this bucket if // it's not its turn to be reduced. if (bucket_index > next_bucket_) { return; }
// Keep going, until we either: // - 所有桶都在 allreduce 那就等着 or // - 还有桶没好,那也等着. for (; next_bucket_ < buckets_.size() && buckets_[next_bucket_].pending == 0; next_bucket_++) { auto& bucket = buckets_[next_bucket_]; std::vector<at::Tensor> tensors; tensors.reserve(bucket.replicas.size()); for (constauto& replica : bucket.replicas) {
defexample(rank, world_size): # create default process group dist.init_process_group("gloo",rank=rank, world_size=world_size,init_method='env://') # create local model model = nn.Linear(10, 10).to(rank) # construct DDP model ddp_model = DDP(model, device_ids=[rank]) # define loss function and optimizer loss_fn = nn.MSELoss() optimizer = optim.SGD(ddp_model.parameters(), lr=0.001)
buf = 0 tmp = 0 for i inrange(10000): start = timer() # forward pass outputs = ddp_model(torch.randn(20, 10).to(rank)) end = timer()
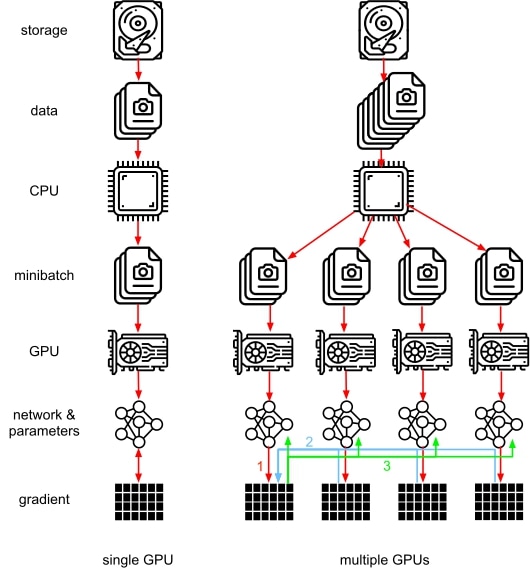

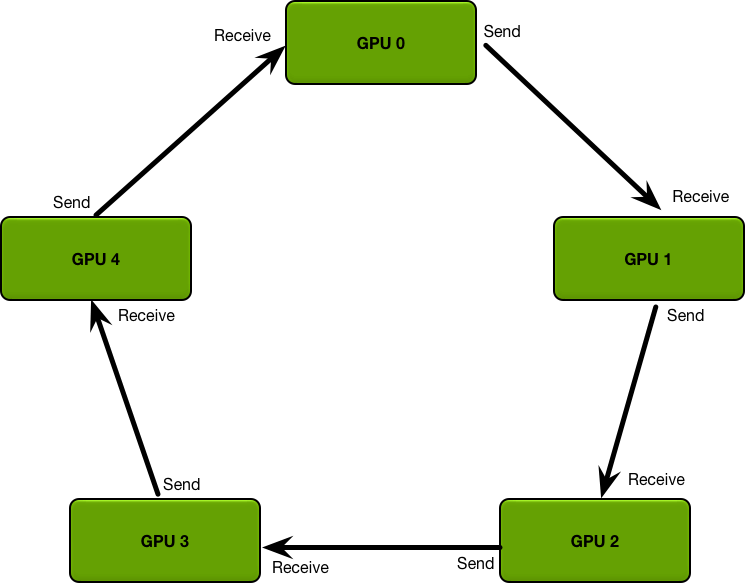
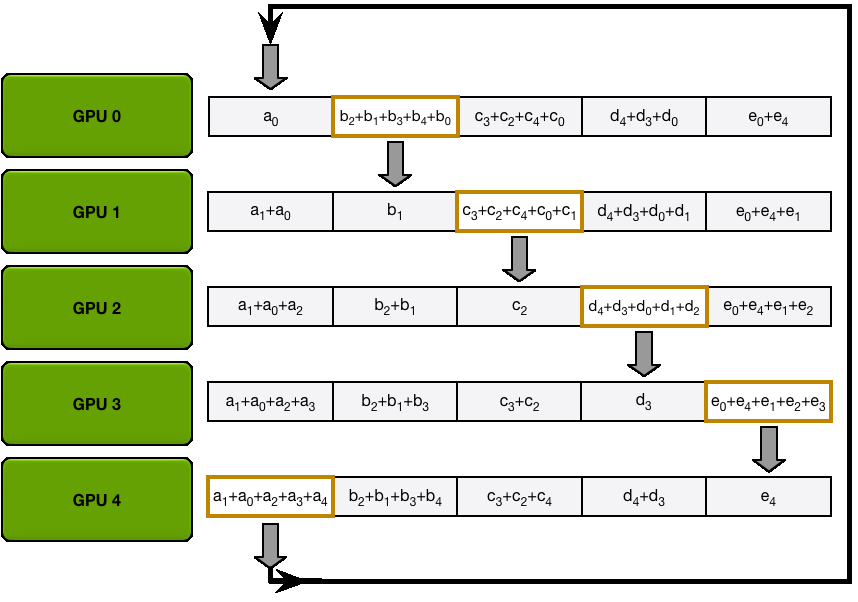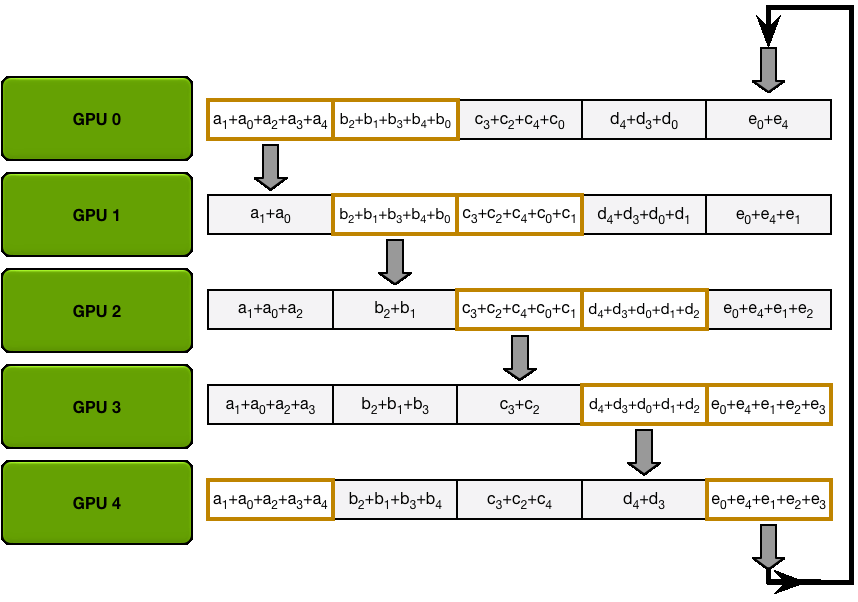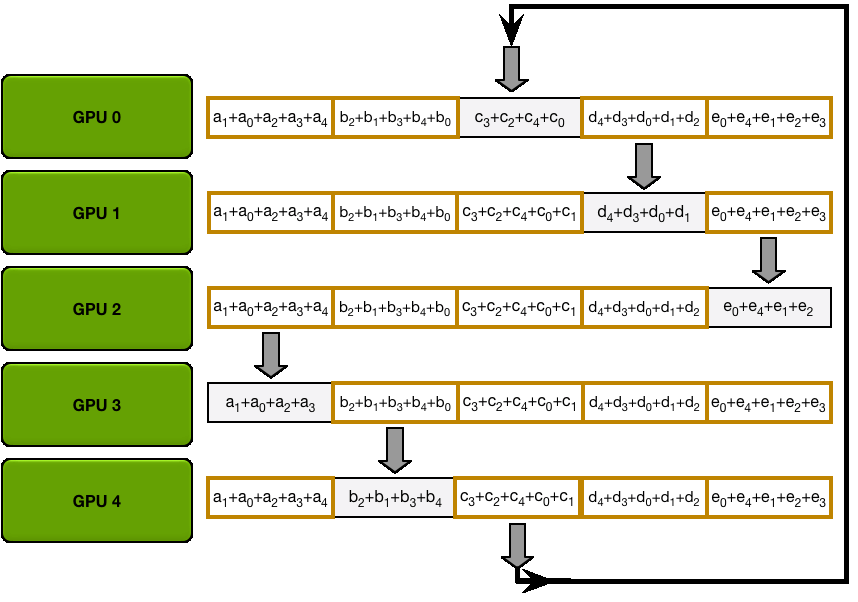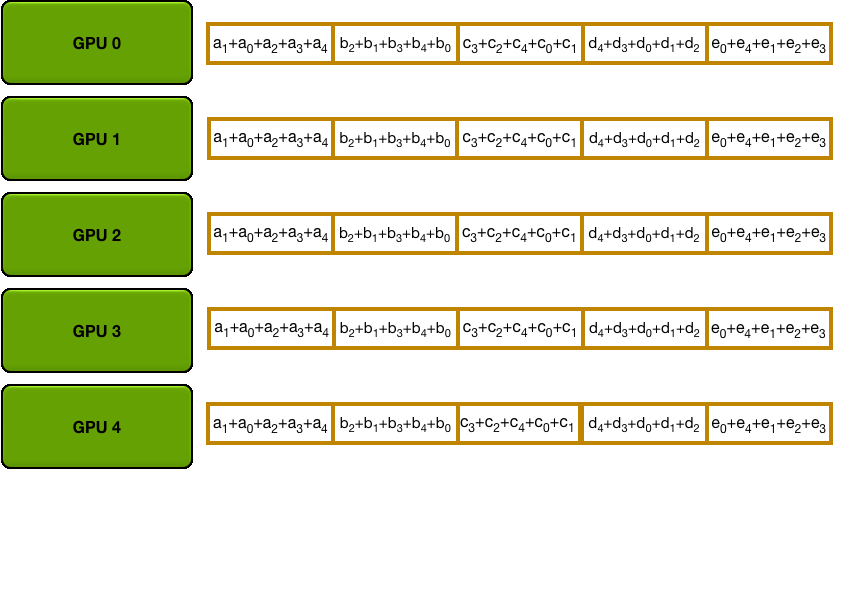
个 GPU, 完成一次通信需要时间
,那么使用 PS 算法,总共需要花费时间